Before we start
Nashorning, I would like to contextualize what I’m trying to do here, I was curious about what kind of data we would see while monitoring a JVM executing the Nashorn Javascript engine, considering the deep technical details behind these untyped dynamic chaotic scripting languages, we should see something interesting, right? So, moved by curiosity, I’ve downloaded the
OpenJDK 8 to start playing with Nashorn and dig more into that. I will share the results of my research but first, let’s talk about how JVM monitoring is done today.
—
Why do we monitor the JVM? Two reasons: Performance & Benchmarking.
Performance: What if your application is slow? Hanging? Is it crashing all of a sudden? Is there some specific event that freezes the entire system for a moment? Yeah.. you must find the root cause of this bottleneck, but how? Don’t worry, I will present a few tools/commands and share a bunch of vague conjectures to leave you even more confused some cool info to get you started on this amazing world of the JVM Monitoring, are you psyched?
Benchmarking: That’s when you take note of a given set of statistics that were generated while monitoring the system was being monitored and then you can use this report to compare how things change over time, i.e., after new patches, releases, etc. It’s an interesting way to avoid being caught with your pants down, if the system is changing over time you need to check if the resources you have will handle the work load.
I want to cover 3 things today:
1) Thread Dumps
2) Heap Dumps
3) Profilers
Cool, now… let’s see some code, shall we?
Thread Dump analysis
import java.io.BufferedInputStream;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
public class TestRaceCondition {
public static void main(String[] args) {
for (int i = 0; i < 10; i++) {
new MyFileReader().start();
}
}
}
class MyFileReader extends Thread {
public static int num = 0;
public void run() {
try {
BufferedInputStream reader = new BufferedInputStream(
new FileInputStream("/home/themarcelor/someFile.txt"));
readThisFile(reader);
} catch (FileNotFoundException e) {
e.printStackTrace();
}
}
public static synchronized void readThisFile(BufferedInputStream reader){
try {
while (reader.available() > 0) {
System.out.print((char) reader.read());
}
System.out.println(num++);
Thread.sleep(20000);
} catch (IOException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
This code is going to create 10 threads and read the contents of “somFile.txt”, you can easily create a dummy file somewhere in your machine and adapt the code to read its lines, now.. let it create a few threads and then let’s take some Thread Dumps.
 |
Questions: Why are we doing this? What is a Thread Dump?
Answer: We are doing this to illustrate how a multi-threading program can, sometimes, face a situation where a given resource will be ‘locked’ by another activity or it won’t be available due to external factors, e.g., a number of connections were borrowed from a JDBC Connection Pool and the database can’t accept any more connections, there will be several threads/transactions waiting on the queue to be processed (just like our threads that will be waiting to read ‘someFile.txt’), that might slow down some activities in your system.
A Thread Dump is like a picture of whatever is going on inside the JVM, it’s a full report of all the Java objects/classes that are being executed at that specific moment, i.e., a bunch of stack traces containing the state of the threads along with information about locks. |
Now, let’s create a small script to generate Thread Dumps:
#!/bin/sh
SLEEP=$1
PID=$2
while : ; do
date
kill -3 $PID
sleep $SLEEP
done
This can be executed like this:
./takeThreadDumps.sh 5 4321
It is going to trigger the SIGQUIT signal against the Process Identifier (PID) 4321 every 5 seconds, it’s interesting to take multiple thread dumps because it help us analyze what happened within a given time-frame, we can identify what has been running for the last 10, 15 or 20 seconds, if some ExecuteThread: ’16’ that is processing some DB activity (e.g., oracle.jdbc.driver.T4CXAResource.doRollback (T4CXAResource.java:648) ) is showing up in 2 Thread Dumps that were taken in the interval of 10 seconds, something strange is going on.. you better call the DBA.
Yes, that’s for linux users, if you are a Windows user ( 😦 ) then you can run the Java command through your DOS prompt and hit [Ctrl] + [Break] to manually generate Thread Dumps, but it’s best to just use a command-line tool called ‘jstack’, it’s OS-independent, e.g.:
$JAVA_HOME/bin/jstack [PID] > td.txt
If you open one of these Thread Dump files, you are going to see something like this:
2013-05-22 12:30:43
Full thread dump Java HotSpot(TM) 64-Bit Server VM (23.7-b01 mixed mode):
“Attach Listener” daemon prio=10 tid=0x00007fddec001000 nid=0x491d waiting on condition [0x0000000000000000]
java.lang.Thread.State: RUNNABLE
“DestroyJavaVM” prio=10 tid=0x00007fde04009000 nid=0x48dc waiting on condition [0x0000000000000000]
java.lang.Thread.State: RUNNABLE
“Thread-5” prio=10 tid=0x00007fde04221000 nid=0x48ef waiting on condition [0x00007fdde36e6000]
java.lang.Thread.State: TIMED_WAITING (sleeping)
at java.lang.Thread.sleep(Native Method)
at MyFileReader.readThisFile(TestRaceCondition.java:40)
– locked <0x00000000db9c5f20> (a java.lang.Class for MyFileReader)
at MyFileReader.run(TestRaceCondition.java:28)
It’s perfectly possible to analyze the file without any tools, or even write some code to ‘squeeze’ the long running threads throughout a given set of Thread Dumps files, however, some tools can speed up the process by organizing the data to make it easier for our eyes, for that, I recommend a too called
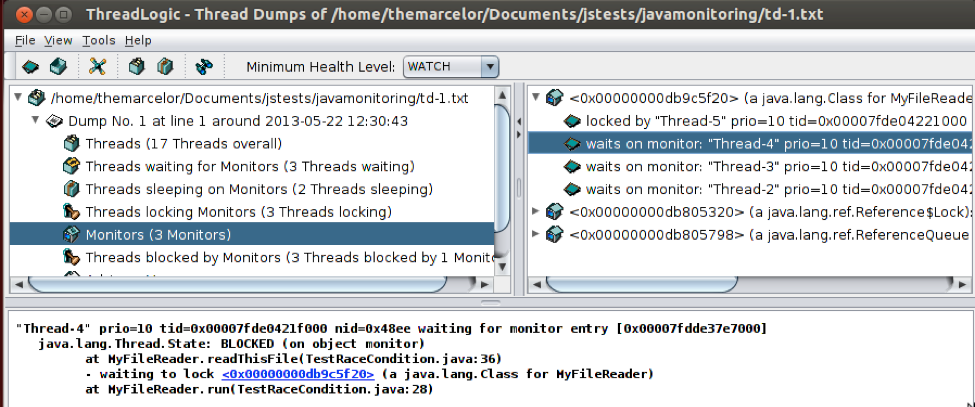
ThreadLogic. Here’s a screenshot of its interface loaded with a Thread Dump from our ‘TestRaceCondition’ program:
So, as you can see, it categorizes the threads to facilitate the analysis, e.g., a useful command there can be found under “tools > Find long running threads…”, I won’t dive too much on its features as it’s pretty intuitive.
Now, about the
Thread Dump Analysis: If you are a Java programmer, all this stuff will be processed by your brain naturally as you already understand Java Threads concepts, such as: synchronized, ‘Wait() & notify()’, sleep(), etc. If you are not a programmer, well.. I personally believe that every IT professional should strive to master two pillars:
Code and Infrastructure, I know many programmers that hate network, server stuff and many systems engineers that hate programming, this has to stop. Anyway, let’s not digress on this philosophical matter, if you are not a programmer and want some rules of thumb I only have one for you:
Look at the monitors.
Imagine the JVM monitor as a supervisor of a construction site, 3 guys need to dig a ditch but they only have one shovel, so they need to take turns (synchronized), the first one grabs (locks/acquire the monitor) the shovel (resource) and the supervisor makes sure that they don’t make a mess and try to do the same thing at the same time (corrupt resource), when the worker gets tired he drops the shovel (release) and call the next guy (notify) that was waiting (wait, duh), some of them can take a nap (sleep) and some of them might wish to keep digging until they finish their part of the job and then allow someone else to take over (join). I hope you got the gist, here’s an image to illustrate this pathetic analogy (yeah.. that thing on the right-side it’s a monitor).

Now, based on these concepts that you learned here, check the Tread Dumps again and share your impressions in the comments section, even better, share your personal experiences with Thread Dump analysis, I bet everyone would find this interesting.
Heap Dump analysis
Heap Dumps are ‘snapshots’ of heap usage, i.e., tables of data indicating how many classes/objects are loaded, how much memory the classes/objects are using and what references they have between each other, these Heap Dump files store information in a very specific format and can only be visualized with Heap Dump Analysis tools, e.g., “Eclipse Memory Analyzer” or “IBM HeapAnalyzer”.
This post is getting quite lenghty so I’m glad I have a bunch of other posts ready to cover this section:
Profilers
Here is where we do the real monitoring, the recording and analysis of the JVM’s internal data is done through a set of tools called ‘profilers’, Profiling is a mechanism whereby one of these tools connect to the JVM through the Java Virtual Machine Tool Interface (JVMTI) to retrieve information about cool JVM stuff, like Threads and Memory (heap) usage.
It also allows a system administrator to send commands to Managed Beans through Java Management Extensions (JMX) methods.
Ok, let’s get down to business, run your java program with the following JVM arguments:
java -Dcom.sun.management.jmxremote.port = 9080 -Dcom.sun.management.jmxremote.authenticate = false -Dcom.sun.management.jmxremote.ssl = false TestRaceCondition
Now you should pick your Profiler, there are many implementations that work with JVMTI, here are a few options:
JRockit is my favorite (
which should be replaced by Java Mission Control soon), the interface is very practical and it’s full of features (Czech out the video!), Visual VM is simpler but has a cool GC log viewer plugin, I’m not a big fan of jConsole but it’s shipped with older versions of the JDK so it might come in handy, Eclipse TPTP gives that feeling of working within the same space, which is good but you will need to download too many things to start using it (it’s pretty cool though), in summary: they’re all awesome! It depends on your mood.
—
Ok, that’s it for today, in the next part of the “Nashorn and the JVM monitoring challenge” series, we will learn more about ‘invokedynamic’ and the bizarre results that we get when we try to monitor/troubleshoot Nashorn-based applications.
Cheers!